Cours+TP - Backuper kubernetes avec Velero
Stratégies de backup dans Kubernetes
Si on le considère en détail, le backup est une opération assez complexe bien que courante et indispensable. Le backup est généralement plein de "tradeoffs" et de choix à mener. De plus dans Kubernetes, les modes d'accès habituels aux serveurs et leur systèmes de fichiers est remis en question par le modèle du cloud de conteneur.
Petit rappel sur deux notions :
Backup physique : un backup "bas niveau" et indépendant de l'application particulière, qui sauvegarde généralement les données brutes de l'application au niveau du système de fichiers ou autre stockage. Le backup physique est une sauvegarde globale qui offre en général peu de flexibilité pour la restauration puisqu'il n'est pas au courant de la structure des données particulière de l'application. Exemple: backuper le dossier de données de Postgresql sur le systeme de fichier du serveur
Backup logique : un backup des "objets" et "structures" de données de l'application qui est intégré et adapté à une application particulière. Le backup logique utilise souvent une fonctionnalité d'export intégré avec l'application. Le fait que le backup soit au courant du fonctionnement de l'application, permet que les objets soient sauvegardés et restaurés avec une granularité flexible et en respectant leur consistance : on peut backup. Exemple: backuper chaque base de données via l'une des fonctionnalité d'export postgres. Cela permet de ne restaurer qu'une application
On combine généralement ces deux stratégies pour plus de sécurité et pour répondre à différents cas d'usage : backup physique et restauration globale en cas de perte des données de tout un serveur (pour les grosses catastrophes), le backup physique est plus simple et souvent "fiable". Backup logique pour les échecs ou erreurs liés à une application particulière. Cela permet de répondre à une catastrophe limitée plus facilement, revenir en arrière sur les données d'une app ou la migrer d'un lieu à un autre.
Dans Kubernetes on peut également combiner ces deux types de stratégies à plusieurs niveaux d'abstraction :
Backup physique des OS/systèmes de fichiers des noeuds du cluster. Surtout utile si etcd et/ou les données des volumes sont présents sur les noeuds. Peu adapté à un cluster vraiment "élastique".
Backup physique de la base de données etcd de Kubernetes. Permet ensuite de restaurer l'état global d'un cluster en cas de problème : https://kubernetes.io/docs/tasks/administer-cluster/configure-upgrade-etcd/#backing-up-an-etcd-cluster. Mais ne permet pas de récupérer les données des applications (volumes et PersistentVolumes)
Backup physique du système de stockage du cluster par exemple Ceph ou AWS EBS, etc. Pour backuper les données brutes des applications (les différents volumes).
Backup logique des volumes. Les opérateurs de stockage comme Longhorn peuvent sauvegarder les volumes de chaque (application/namespace) et les restaurer à la demande.
Backup Logique des objets Kubernetes d'une application, voire d'une partie d'application, et ce idéalement en garantissant la consistance entre les objets et les données/volumes: opérateur de backup comme Velero (ou Veeam Kasten).
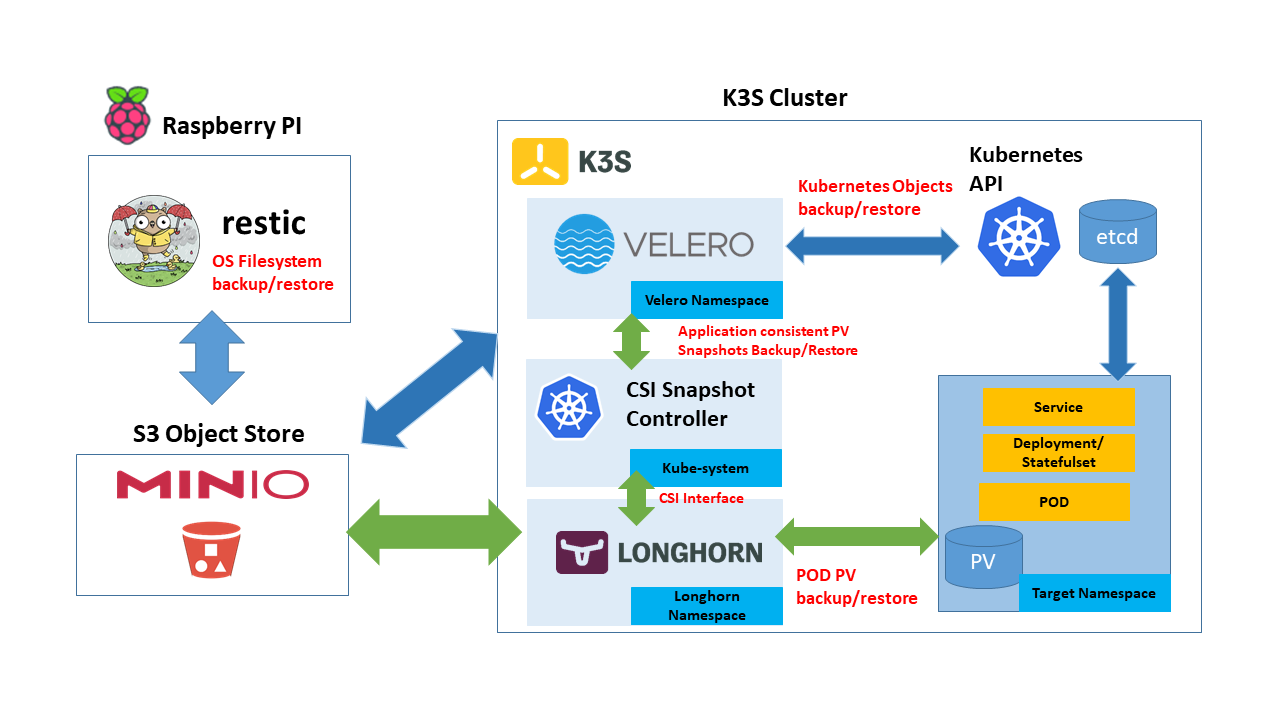
Ici nous allons nous concentrer sur Velero. Mais dans le contexte de notre lab on pourrait également mettre en place un backup de etcd ou des volumes Longhorn.
Velero, opérateur de backup logique
Velero est un opérateur de backup natif kubernetes : il opère pour nous une combinaison d'outils de backub et utilise l'api de Kubernetes pour cela (API kube, snapshot CSI, snapshot aws EBS, kopia ou restic)
Il permet ainsi d'effectuer proprement et confortablement le backup "logique" d'une application dans un namespace ou de tout un cluster. Il permet ensuite de définir des opérations de restauration en cas de désastre ou dans un autre cluster pour migrer une application d'un cluster à l'autre.
Velero est controlable via une CLI et/ou des CRDs
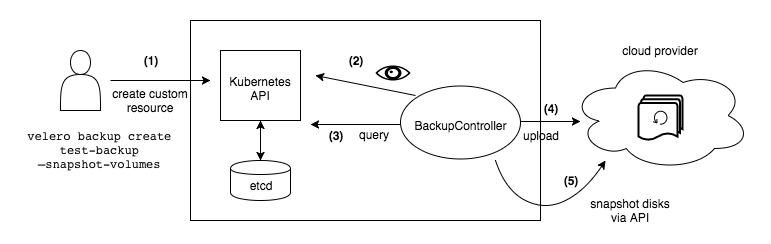
Plus concrêtement dans une configuration simple:
- créé un snapshot ou fichier tar pour la cible à sauvegarder (les manifestes kubernetes mais également les PersistantVolumes associés aux pods pour restaurer l'état)
- envoie ce fichier dans un
storage backendgénéralement S3 (amazon, minio ou garage).
En fait, Velero est flexible (et donc assez complexe), et propose pas mal de configurations différentes possibles qu'on peut ranger en trois grande catégories:
- pas de backup des volumes/données, uniquement des resources Kubernetes. Les volumes sont par exemple laissés à Longhorn ou autre.
- mode "File system backup": backup directement le contenu des volumes via restic/kopia en montant un conteneur de backup dans le pod connecté au volume. avantages: plus générique, s'adapte à tous les types de volumes (https://velero.io/docs/v1.14/file-system-backup) indépendamment du provider. inconvénients: nécessite un accès direct au système de fichier ce qui veux dire des permissions accordées à Velero et un nouveau vecteur d'attaque qui peut être sérieux (besoin par exemple de conteneurs privilégies pour backup de block storages...). pour les autres limitations voir le lien ci-dessus.
- mode "snapshot" : utiliser une fonctionnalité de snapshot des PersistentVolumes si disponible avec le provider de stockage puis backuper ces snapshots. avantages: plus rapide, sauvegarde plus consistante et surtout plus sécurisée car on passe par l'api sans augmenter la surface d'attaque. inconvénients: plus complexe à configurer et moins portable.
Quelques liens pour approfondir:
- https://picluster.ricsanfre.com/docs/backup/
- https://velero.io/docs/v1.14/how-velero-works/
- https://velero.io/docs/v1.14/file-system-backup/
TP partie 1 : installer Velero et Minio pour un S3 de demo
Installer la CLI velero:
Allez sur https://github.com/vmware-tanzu/velero.git pour trouver le numéro de la dernière release, par exemple 1.14.1.
export VELERO_VERSION=1.14.1
cd /tmp
wget "https://github.com/vmware-tanzu/velero/releases/download/v$VELERO_VERSION/velero-v$VELERO_VERSION-linux-amd64.tar.gz"
tar -zvf velero-v$VELERO_VERSION-linux-amd64.tar.gz
mv velero-v$VELERO_VERSION-linux-amd64/velero /usr/local/bin
velero version
Allez dans le projet kube_lab dossier tooling/velero
Déployons maintenant un stockage S3 Minio de démo:
kubectl apply -f examples/minio/00-minio-deployment.yaml
Ce déploiement S3 utilise les crédentials très secure suivants...
[default]
aws_access_key_id = minio
aws_secret_access_key = minio123
...et provisionne automatiquement un bucket nommé velero avec les bonne permissions. Sinon il faudrait configurer tou cela. (par exemple suivre https://picluster.ricsanfre.com/docs/backup/#enable-csi-snapshots-support-in-k3s)
Déployer le snapshotter+CRDs pour activer les snaphots de volumes longhorn
Suivre la documentation INSTALL.md du kube_lab/tooling/longhorn
Installer l'opérateur velero dans le cluster
Nous pouvons maintenant installer Velero via helm et le fichier velero-values.yaml.
Observons et commentons les values d'installation:
on utilise le plugin amazon puisque S3 est un standard (il existe d'autres plugins pour d'autres providers mais S3 est très généralisé)
on configure la connexion au bucket
on force la connexion s3 "path style" car minio ne supporte pas la connexion "object style"
on active l'integration avec le CSI
helm repo add vmware-tanzu https://vmware-tanzu.github.io/helm-charts/helm install velero vmware-tanzu/velero --version 7.2.1 --values=velero-values.yaml
Déployer une application "stateful" d'exemple
Le Manifeste suivant déploie un nginx avec un PVC et ajouter des annotations configurant des hooks de prebackup executés pas Velero avant le backup
---
apiVersion: v1
kind: Namespace
metadata:
name: nginx-example
labels:
app: nginx
---
kind: PersistentVolumeClaim
apiVersion: v1
metadata:
name: nginx-logs
namespace: nginx-example
labels:
app: nginx
spec:
storageClassName: longhorn
accessModes:
- ReadWriteOnce
resources:
requests:
storage: 50Mi
---
apiVersion: apps/v1
kind: Deployment
metadata:
name: nginx-deployment
namespace: nginx-example
spec:
replicas: 1
selector:
matchLabels:
app: nginx
template:
metadata:
labels:
app: nginx
annotations:
pre.hook.backup.velero.io/container: fsfreeze
pre.hook.backup.velero.io/command: '["/sbin/fsfreeze", "--freeze", "/var/log/nginx"]'
post.hook.backup.velero.io/container: fsfreeze
post.hook.backup.velero.io/command: '["/sbin/fsfreeze", "--unfreeze", "/var/log/nginx"]'
spec:
volumes:
- name: nginx-logs
persistentVolumeClaim:
claimName: nginx-logs
containers:
- image: nginx:1.17.6
name: nginx
ports:
- containerPort: 80
volumeMounts:
- mountPath: "/var/log/nginx"
name: nginx-logs
readOnly: false
- image: ubuntu:bionic
name: fsfreeze
securityContext:
privileged: true
volumeMounts:
- mountPath: "/var/log/nginx"
name: nginx-logs
readOnly: false
command:
- "/bin/bash"
- "-c"
- "sleep infinity"
---
apiVersion: v1
kind: Service
metadata:
labels:
app: nginx
name: my-nginx
namespace: nginx-example
spec:
ports:
- port: 80
targetPort: 80
selector:
app: nginx
type: LoadBalancer
- Appliquez avec
kubectlle dossier nginx-example qui est dans le dossiertooling/velerodukube_labou simplement le code ci-dessus via Lens.
- Connectez vous dans le conteneur pour creer un ficheri témoine dans
/var/log/nginx
kubectl get pod -n nginx-example
kubectl exec <nginx-pod> -n nginx-example -it -- /bin/sh
# touch /var/log/nginx/testfile
4) Créez un backup pour tous les objets du namespace nginx-example:
velero backup create nginx-backup --include-namespaces nginx-example --wait
5) Simuler un petit désastre:
kubectl delete namespace nginx-example
6) Vérifiez que les objets sont bien supprimé:
kubectl get deployments --namespace=nginx-example
kubectl get services --namespace=nginx-example
kubectl get namespace/nginx-example
- Créez un objet restore
velero restore create --from-backup nginx-backup
Après la fin de l'opération restore, vérifiez que l'opération est completed et qu'il n'y a pas d'erreur avec la commande
velero restore get
- Vérifiez que le déploiment est bien de retour
kubectl get deployments --namespace=nginx-example
kubectl get services --namespace=nginx-example
kubectl get namespace/nginx-example
- Connectez vous à nouveau au pod pour vérifier que le fichier testfile est présent dans
/var/log/nginx
Planifier un full backup périodique
Pour configuer un full backup journalier du cluster on peut...
... utiliser la cli
velero schedule create full --schedule "0 4 * * *"
Ou créer une custom resource comme suit:
apiVersion: velero.io/v1
kind: Schedule
metadata:
name: full
namespace: velero
spec:
schedule: 0 4 * * *
template:
hooks: {}
includedNamespaces:
- '*'
includedResources:
- '*'
includeClusterResources: true
metadata:
labels:
type: 'full'
schedule: 'daily'
ttl: 720h0m0s
sources: